
Australian Payments Plus moves faster with ChatGPT and Codex
See how Australian Payments Plus uses ChatGPT Enterprise and Codex to move faster through payments complexity. AP+ saves time, improves quality, and keeps human judgment central.
See how Australian Payments Plus uses ChatGPT Enterprise and Codex to move faster through payments complexity. AP+ saves time, improves quality, and keeps human judgment central.
The lab will beam back data to train AI models to predict how proteins behind age-related diseases like Alzheimer’s and certain cancers behave.
Norwegian striker Erling Haaland isn’t just a footballer anymore. He’s become an internet character perpetuated by fans and AI.
You can clip a cover over the cameras, which could be a double-edged sword.
Claude Cowork now keeps working on tasks even after you close your laptop. It’s part of a larger push toward smartphone-controlled agents.
Joshua Achiam spent nearly nine years at OpenAI researching AI safety and made a memorable appearance in the Musk v. Altman trial.
As part of Meta’s Muse Image model rollout, Instagram users with public accounts need to opt out to block AI generations of their content.

Solos announced a new version of its AirGo smart glasses, one that forgoes cameras for a sleeker design and an AI assistant that relies on voice interactions. Last year’s AirGo A5 weighed 36 to 40 grams depending on the frame style, but the new AirGo A6 weigh around 19 grams. Part of the weight savings […]
Forterra has deployed more than 100 of its self-driving ATVs in conflict zones in Ukraine.
The company just raised $7 million in seed funding, and is launching its app for iPhone and Android on Tuesday.
Anthropic’s Claude Cowork is now available on web and mobile for Max subscribers. Until now, Cowork largely lived on a user’s laptop. With the update, users can start a task from their desk, get status updates on their phone, and pick up the finished output later — even if their laptop is closed.
Investor concerns about massive investments outweigh April-to-June earnings fuelled by high memory chip prices
In this tutorial, we build an autonomous AI co-scientist for EGFR C797S inhibitor discovery. We resolve the target through ChEMBL and UniProt, then mine IC50 records into a clean pIC50 dataset. We use RDKit to standardize molecules, compute Morgan fingerprints, and train a scaffold-split Random Forest QSAR model. We interpret potency drivers with SHAP, then recombine BRICS fragments to generate and rank novel candidates.
The post Building a Scaffold-Split Random Forest QSAR Co-Scientist for EGFR Inhibitor Discovery Using ChEMBL, RDKit, SHAP, and BRICS appeared first on MarkTechPost.

OpenAI added two Realtime models to its API. GPT-Realtime-2.1-mini is a mini reasoning model for voice, priced like the earlier gpt-realtime-mini. OpenAI also cut p95 latency by at least 25% through improved caching. Here is what changed, how pricing compares, and how to connect over WebRTC.
The post OpenAI Releases GPT-Realtime-2.1 and GPT-Realtime-2.1-mini for Low-Latency Voice Agents in the API appeared first on MarkTechPost.
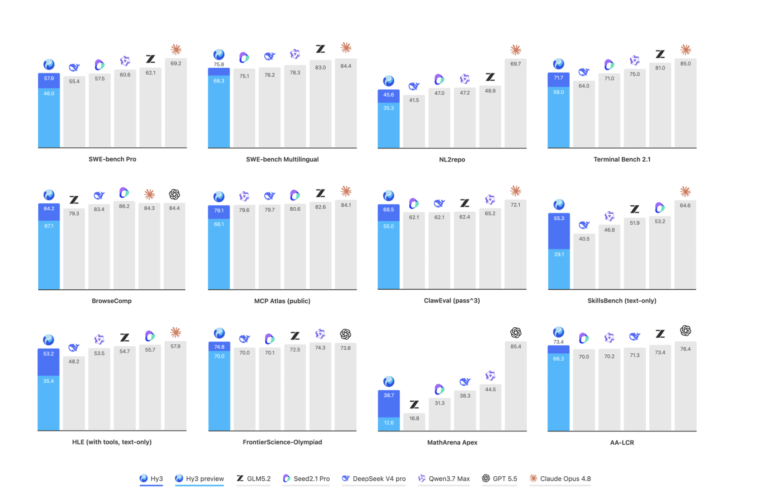
Tencent’s Hy team released Hy3, a 295B Mixture-of-Experts (MoE) model that activates only 21B parameters per token. It ships under Apache 2.0 with a 256K context window, targeting reasoning, agentic, and long-context tasks. Hy3 reports 78.0 on SWE-Bench Verified and lower hallucination rates, and is free to try on OpenRouter through July 21, 2026.
The post Tencent Releases Hy3: An Open 295B Mixture-of-Experts (MoE) Model with 21B Active Parameters and 256K Context appeared first on MarkTechPost.

I’ve long argued that Hollywood has simultaneously set and ruined our expectations for smart glasses. But after binge-watching two seasons of Netflix’s A Man on the Inside, this is perhaps the first time I’ve seen Hollywood, perhaps inadvertently, illustrate the biggest cultural problem with smart glasses as they stand today. In a nutshell, Ted Danson […]
In the AI era, platforms have no choice but to fight fire with fire to cull spam.
Consider this a belated PSA: A recent change to Google’s privacy settings is allowing the company to store more of your data, including media such as “images, files, and audio and video recordings,” to improve its AI models.
The update is part of Apple’s broader effort to make Siri feel more natural and personal, as it rebuilds the assistant around generative AI.
“The reality is, when you’re optimizing for production, you start looking at a price/performance,” Guillermo Rauch tells TechCrunch.
SK Hynix is experiencing a boom credited to AI. It will ride that to a multibillion-dollar U.S. IPO, expected to take place on Friday.
An AI agent carried out the technical execution of a real-world ransomware attack for the first known time, but new details show a human still chose the victim, set up the infrastructure, and supplied stolen credentials — meaning it wasn’t quite the fully autonomous cybercrime debut that last week’s headlines suggested.
Gaming unit under pressure from weak margins and the industry’s sharp hardware downturn
Deal will create a leading advanced materials company with a combined enterprise value of roughly $29bn

In the first half of this year, investors poured $15 billion into seed- through growth-stage rounds for companies in Crunchbase cleantech, EV and sustainability-focused categories. That puts funding on track to slightly exceed the 2025 tally, which was the lowest in several years.
The next step in AI is removing the friction that prevents HR leaders from spending time where they create the most value, including culture.
The post Why HR must lead the AI culture shift appeared first on HR Executive.
Minimum wage increases hit these states and jurisdictions on July 1. Check every rate by work location with our interactive tracker.
The post New July 1 minimum wage rates: Interactive location tracker appeared first on HR Executive.
Republicans and Democrats on the House Energy & Commerce Health Subcommittee joined Thursday to approve a total of 15 health care bills by voice votes.
The post House panel OKs hospital price transparency bills appeared first on HR Executive.
The tech giants are among the pilot partners in RAISE US, a nonpartisan nonprofit aiming set best practices in AI upskilling.
The post Amazon, Microsoft help lead push to reskill workers displaced by AI appeared first on HR Executive.
Microsoft used a voluntary buyout to balance this week’s layoffs. Here’s what the sequencing reveals about workforce planning.
The post Microsoft’s workforce reduction strategy: Buyouts first, layoffs second appeared first on HR Executive.
This story originally appeared in The Algorithm, our weekly newsletter on AI. To get stories like this in your inbox first, sign up here. OpenAI CEO Sam Altman’s oft-discussed promise that Americans will share in the wealth AI creates was in the news again last week. On Thursday, the Financial Times reported that Altman is in…

An AI companion sounds dystopian, but it has become a common thread in the wider conversation about the perils of generative AI. What it refers to is essentially a conversational agent built to sustain an ongoing, personal relationship with a user, with the memory and steady persona that keep it consistent from one session to […]
The post China’s AI companion rules: what Beijing is really going after appeared first on AI News.

A year after cutting around 9,100 employees, Microsoft is making further layoffs today as it begins its new financial year. The software maker is laying off around 4,800 employees today, approximately 2.1 percent of its workforce. Most of the employees affected by today’s cuts are in Microsoft’s commercial sales business or the company’s Xbox division. […]
Station F, a Paris-based startup hub founded by French billionaire Xavier Niel, is gearing up for a new edition of its F/ai accelerator program in a bid to strengthen its positioning as a stepping stone for promising AI startups.
Microsoft cut around 4,800 roles, or 2.1% of its global workforce, on Monday — the latest in a series of layoffs that’s stoking fears of AI replacing jobs. The layoffs will hit Xbox and commercial sales the hardest.